Construire un proxy RSS pour Telegram avec MTProto et GitHub Spec Kit
Je teste depuis plusieurs mois les approches de développement « Spec Driven », qui me semblent promises à un bel avenir grâce à l’essor des IA génératives. Ici, on ne se contente pas de « prompter » un besoin pour voir son code généré : on adopte un nouveau paradigme où la spécification (re)devient la pierre angulaire du projet. On utilise ensuite l’IA pour produire les User Stories, les tâches et, enfin, le code.
- L’intérêt majeur réside dans la conservation de l’intention. On a rarement tendance à historiser ses prompts ; ici, la spécification sert de trace et de garde-fou. On revient en quelque sorte à une méthode Waterfall où la spécification prime, à la différence près que le délai pour obtenir le produit est drastiquement réduit. On passe de plusieurs mois ou années à quelques minutes ou heures pour un résultat équivalent. On peut donc itérer très facilement, directement depuis la spécification.
- Le LLM utilisé a bien sûr son importance, mais la maîtrise de la chaîne de raisonnement offre une plus grande liberté quant à son choix. C’est donc une solution intéressante pour garder le contrôle, voire garantir sa souveraineté.
- Il existe actuellement trois grandes méthodes de développement par IA générative orientées spécifications (vu de ma fenêtre) : BMAD, OpenSpec et GitHub Spec Kit. C’est cette dernière qui me séduit le plus, et que je vais illustrer par la suite.
L’objectif de ce projet est double : mettre en œuvre l’approche Spec Driven Development sur un cas concret — une méthode que j’ai déjà testée et qui me plaît beaucoup — et expérimenter l’utilisation de MTProto. Il s’agit de l’API utilisateur de Telegram qui, contrairement à l’API bot historique, permet de créer un client alternatif, à l’instar du client officiel.
C’est particulièrement utile car le client officiel permet de parcourir un canal auquel on n’est pas abonné, ce qui m’arrive parfois lors de ma veille techno, alors que l’API Bot ne le permet pas. L’idée est de pouvoir être notifié de l’apparition d’une news ou d’un mot-clé sur un canal identifié, sans avoir à s’y abonner ni à interagir.
Le projet consiste donc à transformer n’importe quel canal Telegram public en flux RSS 2.0, sans abonnement, via une API FastAPI asynchrone. La librairie Telethon, qui implémente MTProto, sera utilisée à cet effet.
Le code source du projet avec son historique est disponible sur mon repository GitHub.
Cadre GitHub Spec Kit
Il faut d’abord initialiser un nouveau projet avec GitHub Spec Kit. Pour cela, une fois l’outil installé, il suffit d’exécuter la commande specify init telegram-rss.
Un prompt vous demande alors deux choses :
- Le choix de votre solution d’IA générative. Je dispose de GitHub Copilot, qui sera donc utilisé ici, mais Spec Kit supporte actuellement 18 agents différents.
- Le choix de votre terminal préféré pour l’exécution des commandes.
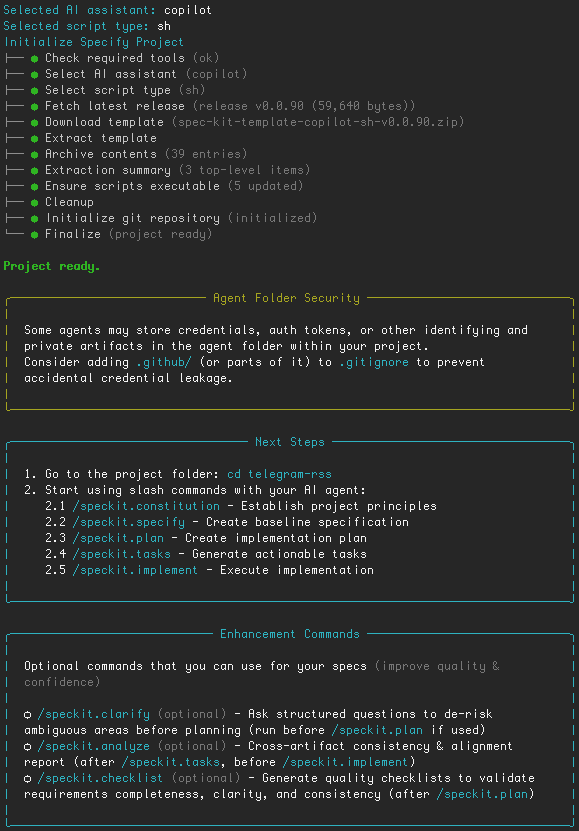
Le dossier ainsi créé peut ensuite être ouvert dans votre éditeur favori (VSCode pour ma part). La première étape consiste à définir les contraintes de constitution du projet. Le fichier constitution.md servira, lors de toutes les commandes ultérieures, à rappeler à l’IA les contraintes et le contexte devant guider ses décisions. La commande :
/speckit.constitution Le programme doit être disponible sous forme d'une image docker, pas besoin de Kubernetes. Pas de base de données externe, si besoin un SQLite peut suffire dans un volume qui sera éventuellement exporté, au même endroit que les paramètres Telegram éventuels. La librairie d'accès à Telegram doit obligatoirement être Telethon (https://docs.telethon.dev/)permet de générer ce fichier. Elle intègre les invariants et les choix techniques sur lesquels on souhaite impérativement s’appuyer.
Spécifications
C’est ici que l’on pérennise le projet. Au lieu de demander directement à une IA de créer le code, on génère d’abord une spécification, un plan et des tâches qui serviront de pivot à tous les développements futurs. Le framework propose des « slash commandes », des prompts augmentés ciblant les modèles les plus performants pour la tâche en cours.
/speckit.specify Cette application est un serveur exposant un flux RSS pour chaque channel telegram demandé, sans que le compte utilisateur Telegram s'y abonne, en utilisant le protocole MTProto de https://docs.telethon.dev/. Le serveur récupère les flux à chaque requête, avec le schéma d'url suivant : http://serveur:port/rss/channel, où channel est remplacé par le nom du channel telegram demandé.Cette commande décrit notre usage. À partir de là, le fichier spec.md est généré. Il doit être attentivement complété par l’humain, car c’est lui qui fixe le cadre de l’implémentation.
À noter : chaque nouvelle spécification est isolée dans un dossier distinct afin de bien séparer les intentions de leur implémentation. C’est propre, clair, et l’intention initiale est parfaitement conservée pour la relecture.
Planification et création des tâches
Les commandes suivantes nécessitent potentiellement moins de prompting, car le besoin est déjà bien défini. Elles doivent permettre de décrire le projet avec assez de précision pour que l’implémentation ne laisse plus de place au doute.
/speckit.plan L'application doit être autonome, en python, et utiliser MTProto de https://docs.telethon.dev/La planification apporte le détail technique. Ici, rien de sorcier : nous avons déjà fourni nos contraintes. J’enfonce le clou, même si c’est probablement superflu.
Maintenant il reste à produire la liste des tâches unitaires nécessaires à l’implémentation, avec la commande /speckit.tasks. Cette liste sera stockée dans tasks.md.
Le résultat est assez bluffant : l’IA découpe le projet en tâches unitaires précises (T001, T002…). C’est votre feuille de route. Vous pouvez l’amender, mais globalement, il ne vous reste plus qu’à piloter l’implémentation, étape par étape.
Implémentation
La commande /speckit.implement, utilisée de manière itérative, permet de dialoguer avec le LLM pour préciser certains points et générer le code. Elle coche automatiquement les tâches complétées dans tasks.md, vous permettant de suivre l’avancement, tests et déploiements inclus.
Pendant l’implémentation, tous les tests sont déroulés. À ce stade, je recommande l’acceptation automatique de certaines commandes dans l’IDE, tant les interactions sont nombreuses. Il faut trouver le juste équilibre entre contrôle humain et rapidité d’exécution.
Pour cette application, les tâches ont été réparties ainsi :
- Setup (T001-T003) : Dépendances (FastAPI, Telethon, feedgen, pytest), Dockerfile unique, arborescence
src/appettests/. - Fondations (T004-T010) :
- Logging JSON structuré.
- Config loader avec fail-fast sur les clés API et les limites.
- Validation des noms de canaux (regex) et modèles.
- Wrapper Telethon (gestion de session, timeout, récupération des messages).
- Générateur RSS (UTF-8, no-store).
- App factory FastAPI et documentation OpenAPI.
- US1 (T011-T013) : Endpoint
GET /rss/{channel}, tests unitaires et intégration. - US2 (T014-T015) : Gestion des erreurs 400/403/404 (invalide, privé ou manquant).
- US3 (T016-T017) : Gestion des timeouts (504) et rate-limits (429).
- Polish (T018-T021) : Quickstart, contrat de test, CI (lint/format) et README complet.
Remarques sur le déroulé avec GitHub Spec Kit
On peut relancer n’importe quelle commande à tout moment. Attention toutefois : cela peut invalider certaines tâches déjà effectuées (ou non), et il faudra parfois rectifier le tir manuellement. Il est primordial de rester attentif aux actions du LLM. Cela représente une vraie charge mentale et nécessite une expertise réelle pour éviter que l’IA ne s’égare.
Erreurs rencontrées et corrections
Voici les quelques accrocs rencontrés lors de la génération automatique. J’ai pu guider l’IA pour les corriger ; les solutions proposées étaient pertinentes, même si cela demande de rester vigilant :
- Import feedgen introuvable : Le serveur lancé avec uvicorn global utilisait le mauvais interpréteur Python. Correction : utiliser python -m uvicorn … pour solliciter l’environnement virtuel.
- RuntimeError « no current event loop » : TelethonClient était instancié de manière synchrone dans init. Correction : rendre get_service asynchrone et opter pour un lazy-init du client. C’était un problème structurel, mais une minute de régénération a suffi à réécrire la version asynchrone. La perte de temps est dérisoire par rapport à un développement humain complet.
- Telethon non autorisé : Erreur 500 attendue sans session active. Solution : création d’un script create_session.py pour générer la session dans le dossier /data.
- Ruff config obsolète : Le champ profile = “black” a été rejeté. Migration vers la nouvelle syntaxe de configuration de Ruff.
- Compatibilité Python 3.10 : datetime.UTC étant indisponible sur cette version, il a été remplacé par timezone.utc.
- Lint B904 : Ajout de from exc lors de la levée d’exceptions HTTP pour préserver la trace.
Résultat final
En seulement 2 heures, j’ai obtenu une première application fonctionnelle répondant à mes attentes. Elle est simple et remplit parfaitement son objectif.
Côté qualité : les tests Ruff/Black sont au vert, 9 tests (unitaires, intégration, contrat) passent avec succès et l’OpenAPI est conforme. Côté Ops, la génération automatique a bien intégré les essentiels (README, Compose, Quickstart). Le volume /data pour la session Telegram est opérationnel et les erreurs HTTP sont correctement mappées. J’ai même ajouté quelques tests de sécurité en CI, configurés pour tourner quotidiennement. Un code généré qui n’évolue plus accumule vite de la dette.
Verdict
Au-delà des spécifications, je remarque que je deviens moins strict sur la « beauté » pure du code. J’exige un contrôle total sur les tests et les garde-fous, mais tant que le code fonctionne, son élégance m’importe moins. C’est une tendance qui devrait s’accentuer : le craftsmanship va évoluer vers la maintenabilité des spécifications plutôt que celle du code lui-même, tant ce dernier peut être réécrit rapidement.
Attention toutefois à la charge mentale : on effectue une code review permanente sur un outil auquel on accorde, par définition, une confiance limitée. C’est un exercice qui demande une concentration soutenue.